Processor micro-architecture internals (branch prediction, branch predictor and indirect branch)
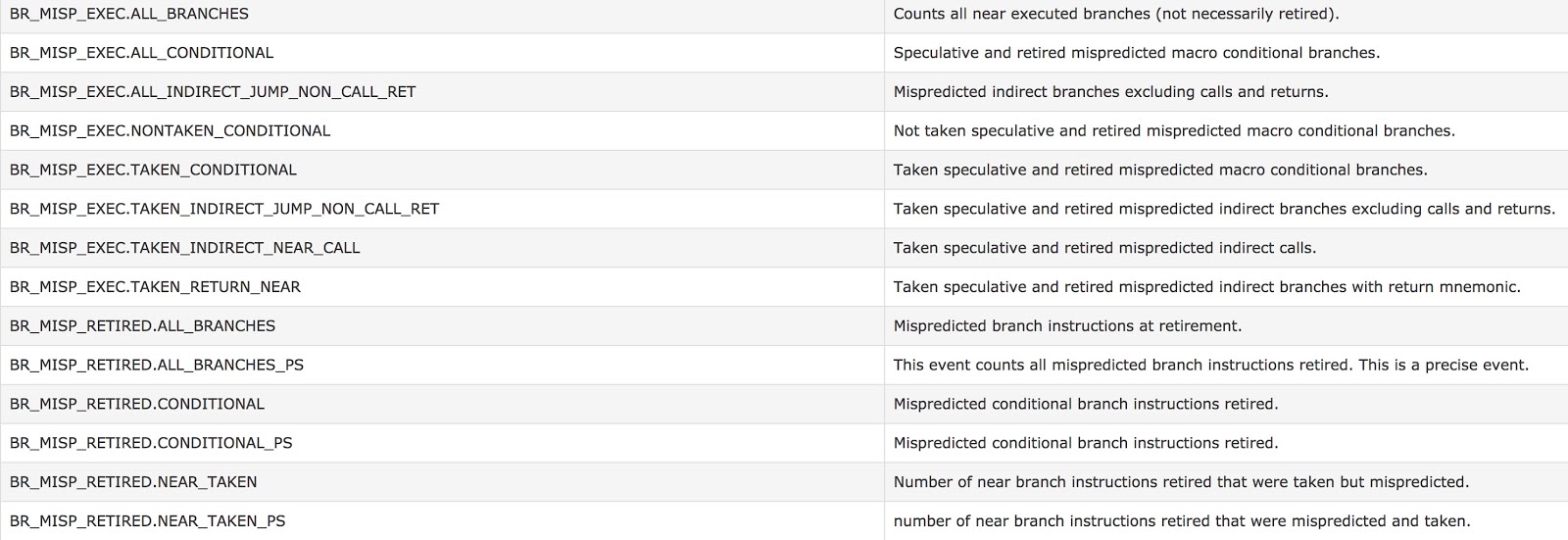
Introduction Recently, our security research on leverage a Performance Monitor Unit as a technique for monitoring a function call and control-flow integrity. We leverage a following perf event , and we faced an interesting problem , Figure[1] The one of the following event is almost always get counted by Performance Counter. BR_MISP_EXEC.TAKEN_INDIRECT_NEAR_CALL The interesting question is that why such instruction is always get mispredicted ? There are couples of things we need to clarify and dive into.... Indirect Branch jmp rax ; Indirect jmp call rax ; Indirect call Branch Target Buffer BTB is a table that in a processor internal, for optimising the processor performance during it's making a branch decision (yes/no), and it is indexed by current RIP (instruction pointer) and the value is branch target address , BTB's structure as following figure Figure[2] Branch Predictor Branch predictor leverages BTB and...